Google Translate is a real-time language translation application that supports input from handwriting, voice, and camera, delivering results as spoken output or text over images. It is powered by Google’s Neural Machine Translation (GNMT) system. This post explores the architecture and technologies behind Google Translate, with a focus on how it uses the Transformer model and various enhancements to improve translation performance.
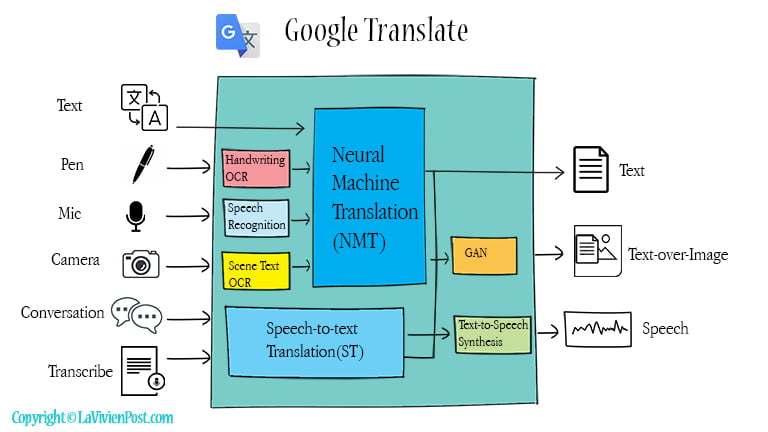
Table of Content
- What are the key components in Google Translate?
- Google Neural Machine Translation(GNMT)
- The transformer model
- Speech-to-Speech Translation(S2ST)
- Optical Character Recognition (OCR)
- Timeline of Google translate
1. What are the key components in Google Translate?
Google Translate is powered by advanced AI technologies built on neural networks. It supports multiple input methods and modes of translation, including:
- Text: Translates written text from one language to another in real time.
- Handwriting (Pen): Recognizes and translates handwritten input.
- Camera: Uses text recognition, machine translation, and image processing to translate text captured through the camera.
- Conversation: Converts spoken language to text, translates it, and then outputs translated speech—enabling real-time multilingual conversations.
- Transcribe: Performs continuous speech-to-text translation for longer spoken content.
Technologies like text-to-text translation, speech recognition, speech-to-text translation, text-to-speech synthesis, handwriting recognition, text recognition, and image synthesis form the core building blocks of Google Translate. Some of these components operate as part of cascaded systems, where each module processes input sequentially. However, many of these cascaded systems are gradually being replaced by more efficient end-to-end models.
2. Google Neural Machine Translation (GNMT)
In the history of machine translation, different approaches were used. There were Rule-based Machine Translation(RBMT), and Statistical Machine Translation(SMT). Since 2014, Neural Machine Translation (NMT) has taken over.
Neural Machine Translation is one of the AI applications under the umbrella of natural language processing (NLP). NLP are technologies to make machines understand and generate human speech or text.
The basic form of neural machine translation is an encoder-decoder architecture. An encoder converts the input words to vectors; a decoder converts vectors to words in another language. In this model, both encoder and decoder use Recurrent Neural Networks (RNN). RNN is a neural network that uses feedback connections to propagate information from one step to the next. In NMT, RNN is a stacked multi-layer of Long short-term memory (LSTM). LSTM is a type of RNN that is capable of performing sequence-to-sequence transfer.
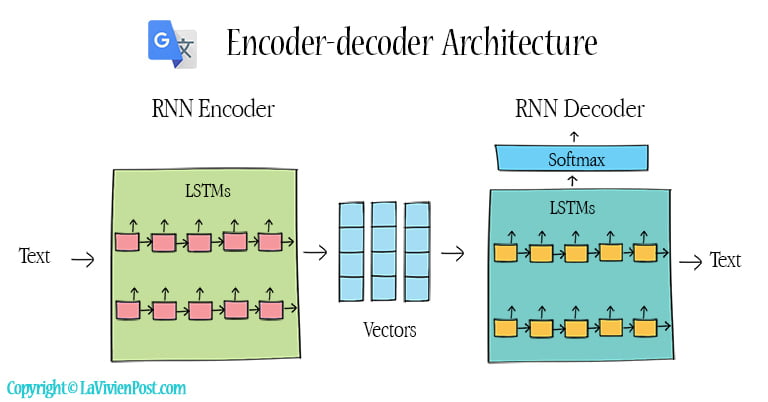
But there are problems with RNN. Different languages have different grammars. The sequence of words in a sentence might not match between languages. Additionally, RNN has difficulty remembering long sentences.
In 2015, an attentional mechanism began to be used in neural machine translation. An attentional mechanism mimicked the humans’ attention to focus on the answer they are looking for and ignore others. This was accomplished by assigning different weights to different words. As a result, it allowed the encoder and decoder to focus on different regions of the sentence. The addition of an attentional mechanism overcomes the “short memory problem” of RNN and LSTM. The new neural network translation system coped effectively with long input sequences.
In 2016, Google pushed out Neural Machine Translation (GNMT). It inherited and enhanced the previous NMT models. Both the encoder and decoder had 8 layers of RNN so that RNN was deep enough to catch subtle irregularities. Each layer ran on different GPUs To improve parallelism.
Meanwhile, there was an attention module sitting between the encoder and the decoder. The attentional mechanism connected the bottom layer of the decoder to the top layer of the encoder to achieve good accuracy.
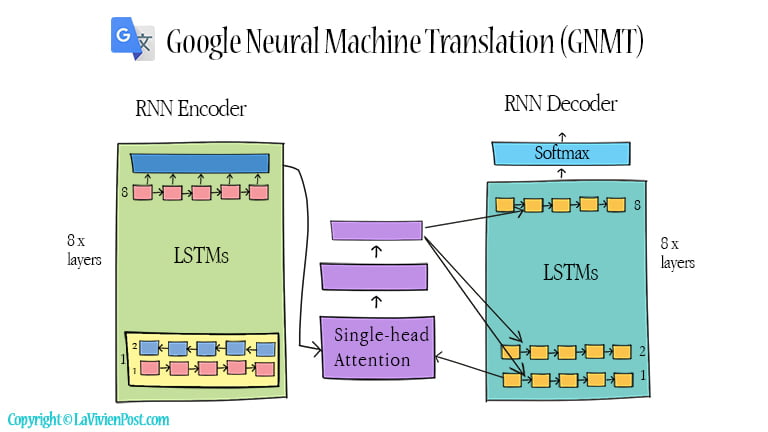
Google team also made other tweaks in their NMT, such as applying one layer of bi-directional LSTM, residual connections, and beam search. All these changes greatly improved the performance of GNMT. A year later, Zero-Shot translation was implemented. The system could translate the language that had never been directly trained on.
3. The transformer model
In 2017, A groundbreaking transformer model was introduced. It was solely based on attentional mechanisms. The phrase “Attention is all you need” means attentional mechanisms were used in both the encoder and decoder. They replaced RNN and CNN completely.
In this model, both encoder and decoder have 6 stacked layers. Each layer has sub-layers of multi-head self-attention and feed-forward. In the decoder, there is an additional sub-layer of multi-head cross-attention. The cross-attention performs an attention function over the output of the encoder layers. This attentional mechanism draws global dependencies between input and output.
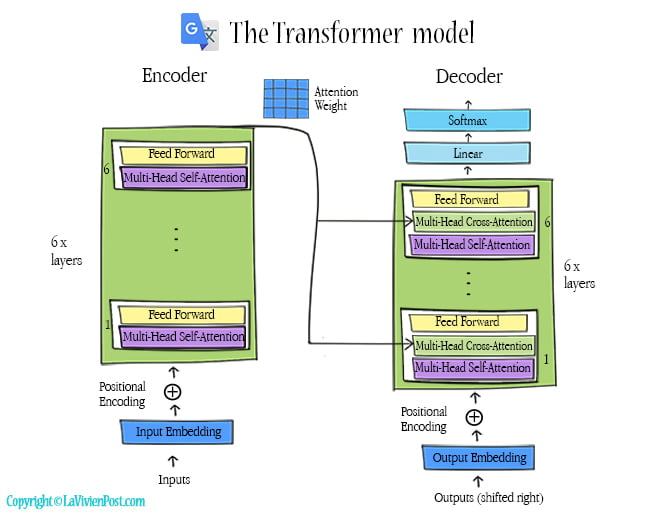
The transformer model is not a sequence-to-sequence transfer as RNN. To remember the relative or absolute position of the words in the sentence, a positional encoding layer is added at the bottom of the encoder or decoder stacks. A self-attention is an attentional mechanism that models relations between all words in a sentence. The attentional mechanism compares the given word to every other word. The result of the comparison is an attention weight for every other word in the sentence.
Since there is no sequence, the self-attention functions can run in parallel. A multi-head self-attention has 8 parallel attention “heads”. Their results are concatenated and projected as the output and sent to a feed-forward network. The parallelization takes full advantage of modern machine learning hardware such as TPUs and GPUs, and it is the key to making the transformer efficient and fast.
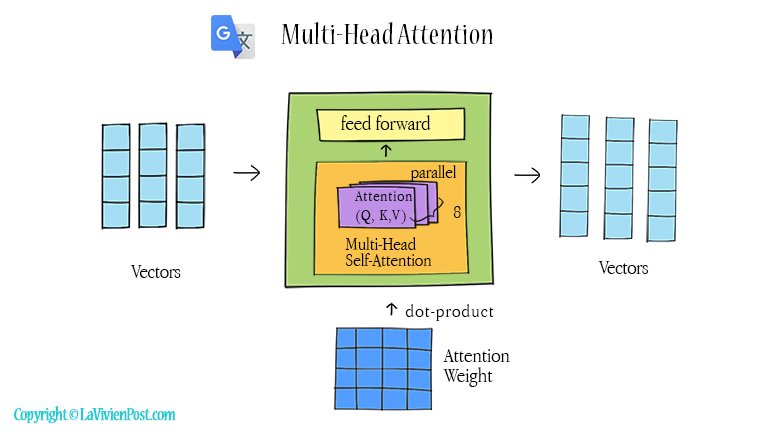
The transformer outperforms both recurrent and convolutional models. It requires significantly less time to train. Many NLP systems, including Google neural networks translation (NMT), Google search query understanding system (e.g., BERT), and text auto-generator (e.g., GPT) have adopted the transformer model.
Nevertheless, the Google translation team continued improving their NMT. In 2018, They introduced hybrid architectures of NMT which combined a transformer encoder and an RNN decoder. They carried on the experiments and found that hybrid models, mixed with transformer and RNN horizontally and vertically in the encoder, performed the best.
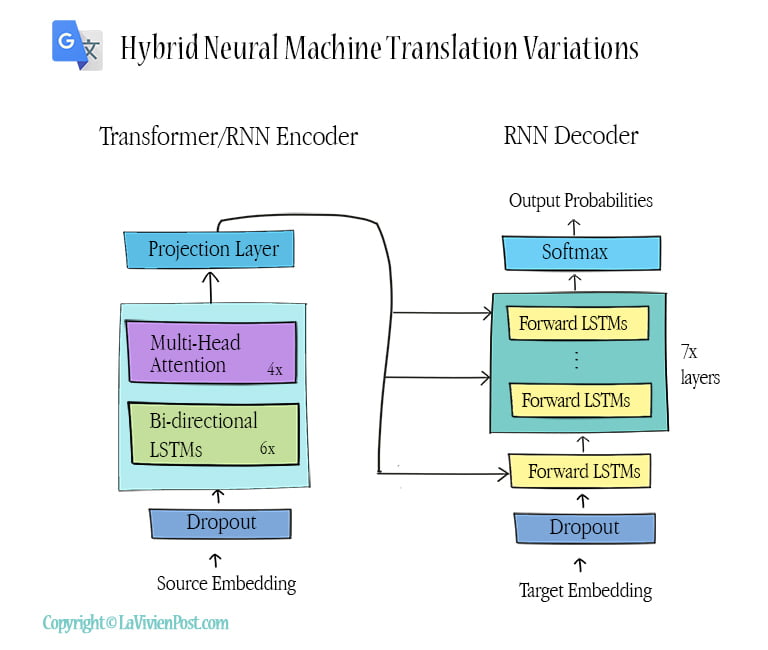
GNMT provides reliable quality text-to-text translation. It also plays as a middleman in the speech translation and image translation.
4. Speech-to-Speech Translation (S2ST)
In the past, conversation translation used a cascaded system of three components: automatic speech recognition(ASR), text-to-text machine translation (MT), and text-to-speech(TTS) synthesis. The ASR and machine translation were combined into a single end-to-end Speech-to-text translation (ST) system.
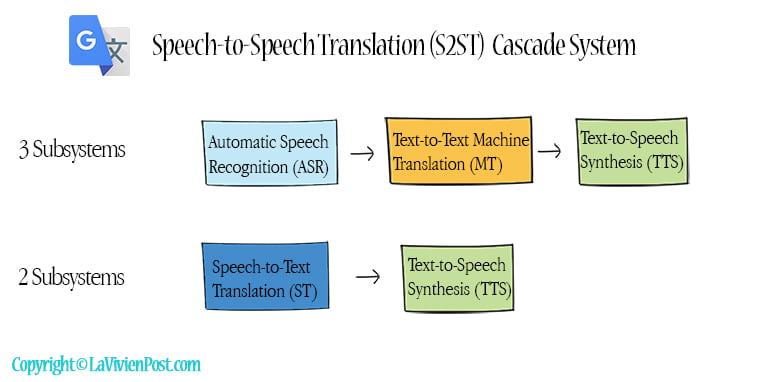
In a speech-to-text translation (ST) system, the encoder has pre-trained ASR, and the decoder has pre-trained MT. After the translated texts are generated, they are sent downstream, which is text-to-speech synthesis (TTS). In this graph, TTS uses the Google Tacotron 2 model.
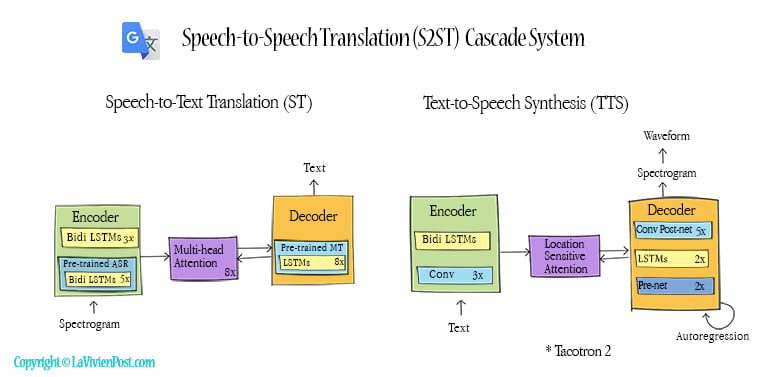
In 2019, Google introduced the first direct speech-to-speech translation, called translatotron. Translatotron could translate speech from one language to speech in another language, without the intermediate text representation. This system was also able to retain the source speaker’s voice. In 2022, Google pushed out translatotron 2. It outperformed translation and approached the performance of the cascaded system.
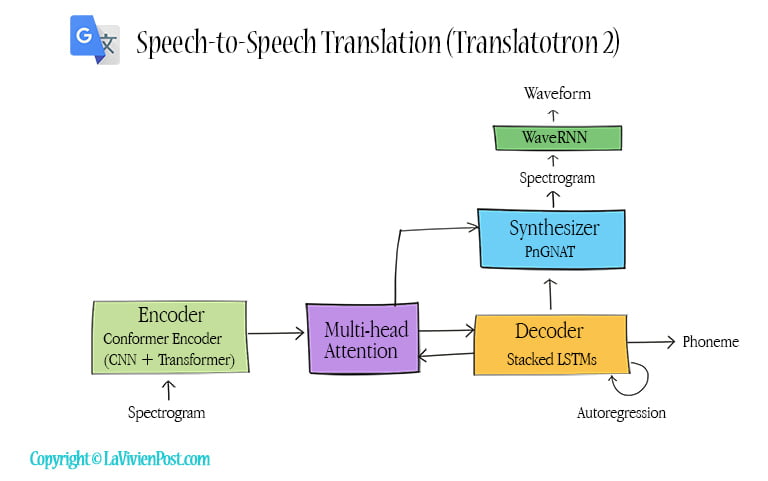
In this model, the encoder contains a speech recognition system Conformer. The conformer combines convolution neural networks (CNN) and transformers. The decoder uses multi-layer LSTMs. It generates linguistic information. A single multi-head attention sits between the encoder and decoder.
A synthesizer performs speech synthesis using a duration-based system Non-Attentive Tacotron (NAT). The synthesizer is conditioned on the output from both the decoder and the attention. After the synthesizer generates spectrograms, a neural vocoder, such as WaveNet or WaveRNN, converts spectrograms to time-domain waveforms.
5. Optical Character Recognition (OCR)
Google Translate provides handwriting and instant camera translation. The technology behind both is optical character recognition (OCR). OCR is a collection of technologies to automatically detect and recognize the texts on paper or in the wild, and turn them into a digital format that computers can edit, search, and store.
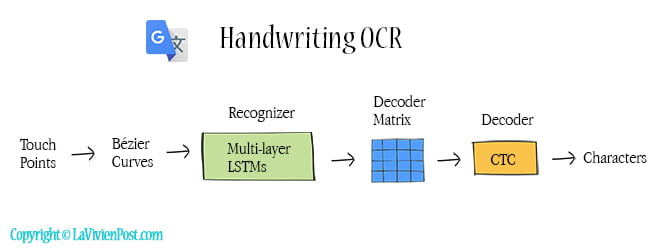
Let’s look at handwriting OCR first. When you tap the pen icon in Google Translate and write characters, The app displays possible letters or words. You can select one of them. Internally, the touch points are the input. The first step is to convert the sequence of points into a sequence of cubic Bezier curves. Next, a multi-layer recurrent neural network (RNN) converts the curves into the matrix with a probability distribution over all possible letters. Then the CTC decoder outputs the characters. Connectionist temporal classification (CTC) is an algorithm that allows the output labels to be aligned with the input sequence.
The instant camera translation allows you to point the camera at documents or public signs and translate them. The pipeline includes OCR, machine translation, and image synthesis. The text detection uses a region proposal network (Convolutional model) to extract the text in the image and put the bounding boxes around the text. The texts are isolated from the background objects. Then the text recognition uses NLP-based networks (CNN and LSTM networks) and CTC to convert the extracted information to construct meaningful sentences.
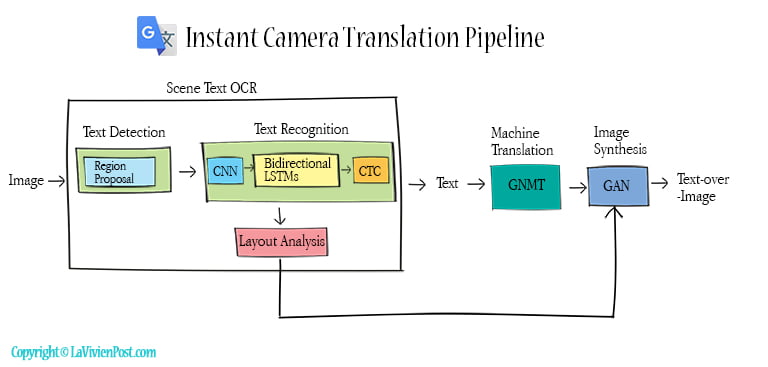
When OCR identifies characters, it also determines the metadata, such as size, font, color and camera angle. This process is called layout analysis.
The recognized texts are fed into GNMT for translation. Down the pipeline, the translated texts are rendered on top of the original text in the same style, matching the original font, size, and length. It also uses generative adversarial networks (GAN) to rebuild the pixels underneath to make the translation look natural. GAN is a type of deep learning model used to generate synthetic data samples that are similar to a training dataset.
In 2020, the researchers proposed an end-to-end in-image neural machine translation. The proposed system could potentially improve the overall quality of image translation.
6. Timeline of Google translate
| 2006 | Google launched Google Translate, which used statistical machine translation. |
| 2011 | Google Brain started neural networks in NLP. |
| 2015 | Google launched handwriting input. |
| 2015 | Attention mechanism began to be used in NMT. |
| 2016 | Google’s Neural Machine Translation was introduced. |
| 2016 | WaveNet – The first model to generate human-like natural waveform. |
| 2017 | Transformer model – use Attention mechanisms to replace RNN and CNN. |
| 2018 | Hybrid models of Transformer and RNN in GNMT |
| 2019 | Translatotron- The first direct speech-to-speech translation model. |
| 2020 | In-image translation – A proposal of direct image-to-image translation model. |
| 2022 | Translatotron 2- An improved direct speech-to-speech translation model. |
How Google Translate works (YouTube)





