ChatGPT’s Large language models includes GPT-3, InstructGPT, ChatGPT, and GPT-4 etc. This post explains the models, including ChatGPT architecture diagram.
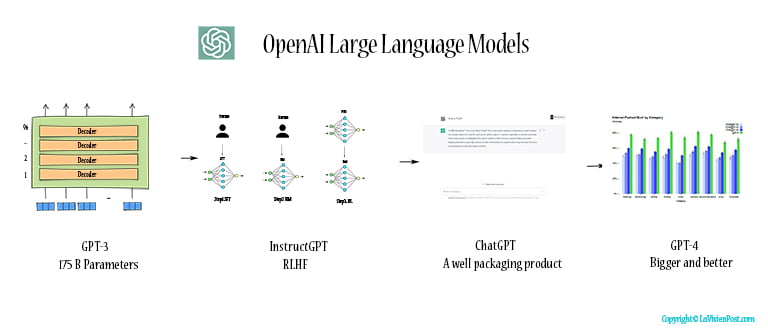
Table of Content
- GPT-3: Introduce Large Language Model
- InstructGPT: Reinforcement learning with human feedback
- ChatGPT: Utilization is the king
- GPT-4: Introduce Artificial Generative Intelligence (AGI)
- OpenAI Timeline and FAQ
1. GPT-3: Introduce Large Language Model
The transformer model was introduced in 2017. Since then, OpenAI pushed out GPT-1 and GPT-2 in 2018 and 2019 respectively based on the transformer model.
From PLM to LLM
GPT-2 is a Pre-trained Language Model (PLM), which is to pre-train transformer models over large-scale corpora. PLMs show strong capabilities in solving various Natural Language Processing (NLP) tasks.
Fast forwarding to 2020, the capacity of transformer language models had increased substantially, from 100 million parameters to 175 billion parameters. OpenAI named the model with 175 B parameters “GPT-3”. The research community coined the term Large Language Models (LLMs)for the PLMs of significant size, e.g., containing tens or hundreds of billions of parameters, trained on massive text data.
GPT-3 achieves strong performance on many NLP tasks, including translation, question-answering, reading comprehension, textual entailment, and many others.
Scaling Law
Researchers have found that model scaling can lead to performance improvement. When the parameter scale exceeds a certain level, they show special abilities that are not present in small-scale language models.
Scaling law refers to scaling PLM (both model size and data size) often leads to an improved model capacity on downstream tasks. These large-sized PLMs display different behaviors from smaller PLMs and show surprising abilities (called “emergent abilities”) in solving a series of complex tasks.
Emergent abilities of LLMs are formally defined as “the abilities that are not present in small models but arise in large models,” which is one of the most distinctive features that distinguish LLMs from previous PLMs. It also introduces a notable characteristic when emergent abilities occur: performance rises significantly above random when the scale reaches a certain level.
Despite the progress and impact, the underlying principles of LLMs are still not well explored. It is still mysterious why emergent abilities occur in LLMs, instead of smaller PLMs. Some abilities, e.g., in-context learning, are unpredictable according to the scaling law.
Datasets
By pre-training on a mixture of text data from diverse sources, LLMs can acquire a broad scope of knowledge and may exhibit a strong generalization capacity. When mixing different sources, one needs to carefully set the distribution of pre-training data, since it is also likely to affect the performance of LLMs.
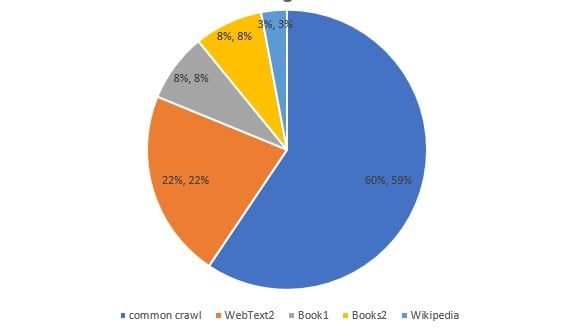
According to GPT-3 paper, GPT-3’s datasets include CommonCrawl, WebText2, Books1, Books2, and Wikipedia. CommonCrawl is one of the largest open-source web crawling databases, containing a petabyte-scale data volume, which has been widely used as training data for existing LLMs. The English-only filtered versions of Wikipedia are widely used in most LLMs. As for Books1 and Books2, they are much larger than BookCorpus used in GPT-1 and GPT-2.
Although it is not showing in GPT-3 datasets, code is added as part of the datasets as well. The code data is from existing work that crawls open-source licensed codes from the Internet. Two major sources are public code repositories under open-source licenses, e.g., GitHub, and code-related question-answering platforms, e.g., StackOverflow.
Given a more diverse knowledge base, a model shows the capability to perform an even wider range of tasks.
Architecture
In general, the existing LLMs can be categorized into encoder-decoder architecture and newly decoder-only architecture.
The original Transformer model is built on the encoder-decoder architecture, which consists of two stacks of Transformer blocks as the encoder and decoder respectively. The encoder adopts stacked multi-head self-attention layers to encode the input sequence for generating its latent representations, while the decoder performs cross-attention on these representations and autoregressively generates the target sequence.
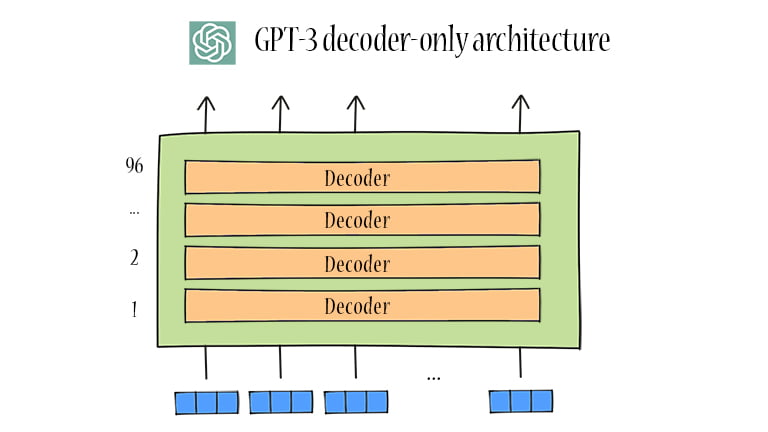
Since most language tasks can be cast as the prediction problem based on the input, the decoder-only LLMs are potentially advantageous to implicitly learn how to accomplish the tasks in a unified way. GPT-2 and GPT-3 use a casual decoder architecture (see the diagram below). In GPT-3, there are 96-layer transformer decoders. When mentioning “decoder-only architecture,” it often refers to the casual decoder architecture.
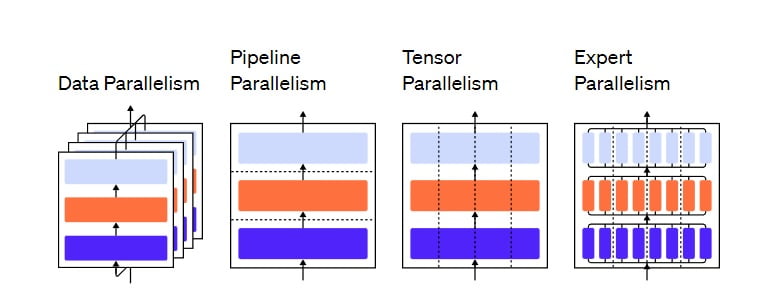
Models of this scale typically require thousands of GPUs or TPUs to train. To support distributed training, several optimization frameworks have been released to facilitate the implementation and deployment of parallel algorithms.
Courtesy of OpenAI
2. InstructGPT: Reinforcement learning with human feedback
LLMs have shown remarkable capabilities in a wide range of NLP tasks. However, these models may sometimes exhibit unintended behaviors, e.g., fabricating false information, pursuing inaccurate objectives, and producing harmful, misleading, and biased expressions. For LLMs, the language modeling objective retrains the model parameters by word prediction while lacking the consideration of human values (helpful, honest, harmless) or preferences. To avert these unexpected behaviors, human alignment has been proposed to make LLMs act in line with human expectations.
RLHF overview
In early 2022, InstructGPT was introduced to address the above problem. OpenAI designed an effective tuning approach that enables LLMs to follow the expected instructions, which utilizes the technique of Reinforcement Learning with Human Feedback (RLHF). It was to incorporate humans in the training loop with elaborately designed labeling strategies.
This technique used human preferences as a reward signal to fine-tune LLMs. OpenAI hired a team of 40 contractors to label the data, based on their performance on a screening test. Then trained a reward model (RM) on this dataset to predict which model output labelers would prefer. Finally, this RM was used as a reward function and fine-tuned the supervised learning baseline to maximize this reward using the Proximal Policy Optimization (PPO) algorithm.
InstructGPT generates more appropriate outputs, and more reliably follows explicit constraints in the instruction. Outputs from the 1.3B parameter InstructGPT are preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters. Moreover, InstructGPT shows improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions on public NLP datasets.
RLHF steps
The RLHF system comprises three key components: a pre-trained LM to be aligned, a reward model learning from human feedback, and a Reinforcement Language algorithm training the LM.
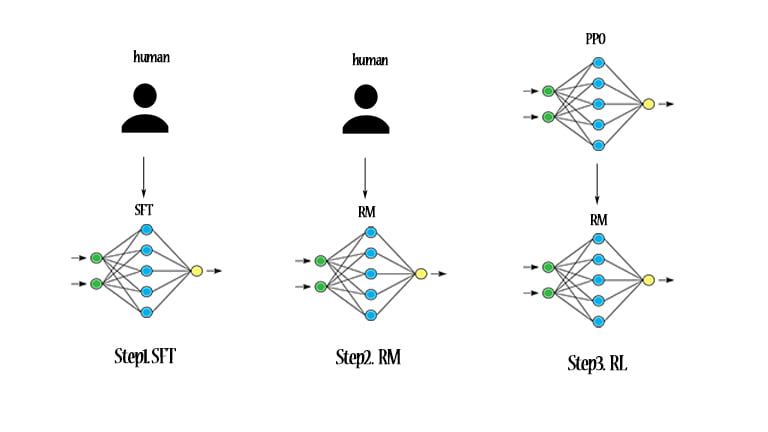
Courtesy of OpenAI
There are 3 steps in RLHF:
Step 1: Supervised fine-tuning (SFT)
Collect demonstration data, and train a supervised policy. The labelers provide demonstrations of the desired behavior on the input prompt distribution. Then the team fine-tunes a pretrained GPT-3 model on this data using supervised learning.
Step 2: Rewording model training(RM)
Collect comparison data, and train a reward model. The team collects a dataset of comparisons between model outputs, where the labelers indicate which output they prefer for a given input. Then trains a reward model to predict the human-preferred output.
Step 3: Reinforcement Learning fine-tuning (RL)
Optimize a policy against the reward model using PPO. The team uses the output of the RM as a scalar reward. Then fine-tunes the supervised policy to optimize this reward using the Proximal Policy Optimization PPO algorithm.
Steps 2 and 3 are iterated continuously; more comparison data is collected on the current best policy, which is used to train a new RM and then a new policy. In practice, most of the comparison data comes from supervised policies, with some coming from PPO policies.
3. ChatGPT: Utilization is the king
In late 2022, The launch of ChatGPT attracted widespread attention from society. ChatGPT is a powerful AI chatbot developed based on LLMs and presents an amazing conversation ability with humans.
ChatGPT is the outcome of the continuous evolvement of previous LLMs, e.g., GPT-3 and InstructGPT. It is a product that is actually helpful to humans.
Prompting
Prompting has become the prominent approach to using LLMs. In-context learning (ICL), a special prompting form, is first proposed along with GPT-3. ICL uses a formatted natural language prompt, consisting of the task description and a few task examples as demonstrations. Since the performance of ICL heavily relies on demonstrations, it is an important issue to properly design them as part of the development in GPT-3.
ChatGPT applies interactive prompting mechanisms, e.g., through natural language conversations, to solve complex tasks. These have been demonstrated to be very useful.
NLP tasks
ChatGPT shows the capabilities in a wide range of applications, such as dialogue systems, text summarization, machine translation, code generation, etc. Here are some major capabilities of NLP tasks in ChatGPT.
ChatGPT also shows a feasible way to learn from existing LLMs for incremental development or experimental study. The incremental tasks include writing a summary of a text, answering factual questions, composing a poem based on a given rhyme scheme, or solving a math problem that follows a standard procedure.
Good packaging
Thanks to RLHF from its predecessor InstructGPT, ChatGPT shows a strong alignment capacity in producing high-quality, harmless responses, e.g., rejecting to answer insulting questions. Sometimes it gives the impression that you are talking to a well-trained customer service representative.
You may also notice ChatGPT’s user interface is more attractive than other similar products, such as Bing’s chat, Google’s Bard, and Meta’s Blender Box 3.
Unlike Meta’s Blender box3 or Microsoft’s Bing chat, ChatGPT does not use the format of messaging, left and right dialog boxes. Instead, ChatGPT is formatted as question-and-answer fields. In this format, users get longer and more formal answers.
Unlike Google’s Bard, which displays the answer all at once, ChatGPT uses animation to display words by words. It gives an illusion that somebody is thinking and typing.
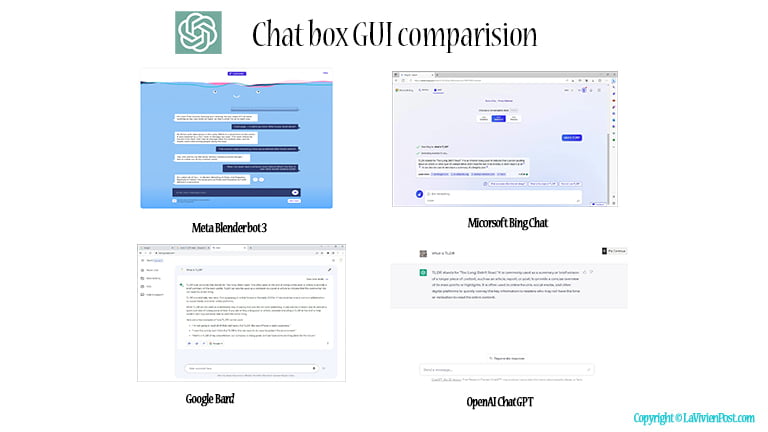
All these details make ChatGPT an outstanding and well-received product.
ChatGPT also supports the use of plugins, which can equip LLMs with broader capacities beyond language modeling. For example, the web browser plugin enables ChatGPT to access fresh information. By incorporating the extracted relevant information into the context, LLMs can acquire new factual knowledge and perform better on relevant tasks.
4. GPT-4: Introduce Artificial Generative Intelligence (AGI)
The latest model from OpenAI is GPT-4. GPT-4 is a large-scale, multimodal model which can accept image, and text inputs, and produce text outputs. GPT-4 exhibits human-level performance on various professional and academic benchmarks.
OpenAI did not give out GPT-4 details about the architecture, including model size, hardware, training compute, dataset construction, training method, etc. However, GPT-4 was certainly trained using an unprecedented scale of computing and data.
GPT-4 outperforms ChatGPT
GPT-4 demonstrates remarkable capabilities in a variety of domains and tasks, including abstraction, comprehension, vision, coding, mathematics, medicine, law, understanding of human motives and emotions, and more. It is also able to combine skills and concepts from multiple domains with fluidity, showing an impressive comprehension of complex ideas.
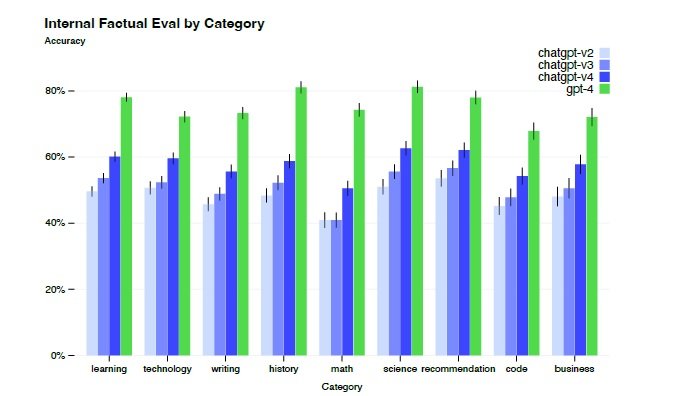
Courtesy of OpenAI
GPT’s performance in exams often vastly surpasses prior models ChatGPT. Meanwhile, To improve the model safety, RLHF is continuously carried out in GPT-4. GPT-4 significantly reduces hallucinations relative to previous ChatGPT, which have themselves been improving with continued iteration.
GPT-4 has also introduced a new mechanism called predictable scaling built on a deep learning stack, enabling the performance prediction of large models with a much smaller model, which might be quite useful for developing LLMs.
GPT-4 archives AGI
GPT-4 exhibits more general intelligence than previous AI models. GPT-4 approaches human-level performance in a variety of challenging tasks across various fields and is considered “an early version of an Artificial General Intelligence system”. It is the first step towards a series of increasingly generally intelligent systems.
More work to do
GPT-4 still has many limitations. In some areas, GPT-4 does not perform well. In particular, it still suffers from some of the well-documented shortcomings of LLMs such as the problem of hallucinations or making basic arithmetic mistakes.
LLMs are also likely to produce toxic, fictitious, or harmful content. It requires effective and efficient control approaches to eliminate the potential risks of the use of LLMs, such as bias, disinformation, over-reliance, privacy, cybersecurity, proliferation, and more.
Due to the limitations of the next-word prediction paradigm, which manifest as the model’s lack of planning, working memory, ability to backtrack, and reasoning abilities. The model relies on a local and greedy process of generating the next word, without any global or deep understanding of the task or the output. Thus, the model is good at producing fluent and coherent texts but has limitations with regard to solving complex or creative problems that cannot be approached in a sequential manner.
A lot remains to be done to create a system that could qualify as a complete AGI, including the possible need to pursue a new paradigm that moves beyond next-word prediction.
OpenAI invites many experts in domains related to AI risks to evaluate and improve the behaviors of GPT-4 when encountering risky content.
5. OpenAI Timeline
| 2018 | GPT-1, A Generative Pre-trained Transformer (GPT) |
| 2019 | GPT-2, A Pre-trained language model (PLM) |
| 2020 | GPT-3, A Large language model (LLM) |
| Nov 2021 | WebGPT, A browser-assisted question-answering with human feedback |
| Mar 2022 | InstructGPT, Reinforcement learning with human feedback(RLHF) |
| Nov 2022 | ChatGPT, A well received product |
| Mar 2023 | GPT-4, First step to Artificial General Intelligence (AGI) capabilities |
ChatGPT’s datasets are a mixture of text data from diverse sources, including CommonCrawl, WebText2, Books1, Books2, Wikipedia, and code from GitHub and StackOverflow.
ChatGPT’s Reinforcement Learning with Human Feedback(RLHF) has 3 steps: Supervised fine-tuning, Rewording model training, and Reinforcement Learning fine-tuning. The first two steps have humans involved. The last step uses the Proximal Policy Optimization (PPO) algorithm in reinforcement learning.
ChatGPT architecture is built on the Transformer model, which is an encoder-decoder architecture. Since most language tasks can be cast as the prediction problem based on the input, ChatGPT (GPT-2, GPT-3) changes to decoder-only architecture with many more layers.
Unlike Google’s Bard, which displays the answer all at once, ChatGPT uses animation to display words by words. It gives an illusion that somebody is thinking and typing. People like this kind of “thinking and action” mode.
How ChatGPT works (YouTube)
How Google Translate works





