When you search in Google, it provides autocorrect for validating the keywords you enter into the input box. Behind the scene, it checks the input words against a dictionary. If it doesn’t find the keyword in the dictionary, it suggests a most likely replacement.
Here I introduce a simple solution to implement autocorrect. To do this, the program associates with every word in the dictionary a frequency, the percent of the time that word is expected to appear in a large document. When a word is misspelled (i.e. it is not found in the dictionary), the program suggests a “similar” word whose frequency is larger or equal to any other “similar” word.
For implementation, first you can implement the dictionary as a Trie. A Trie is a tree-based data structure designed to store items that are sequences of characters from an alphabet. Each Trie-Node stores a count and a sequence of Nodes, one for each element in the alphabet. Each Trie-Node has a single parent except for the root of the Trie which does not have a parent. A sequence of characters from the alphabet is stored in the Trie as a path in the Trie from the root to the last character of the sequence.
Edit Distances is the key part to define the similarity of two words. In computer science, it is a way to measure the number of different letters between two strings. There are four Edit Distances:
● Deletion Distance: 1 from “bird” are “ird”, “brd”, “bid”, and “bir”.
● Transposition Distance: 1 from “house” are “ohuse”, “huose”, “hosue” and “houes”.
● Alteration Distance: 1 from “top” are “aop”, “bop”, …, “zop”, “tap”, “tbp”, …, “tzp”, “toa”, “tob”, …, and “toz”.
● Insertion Distance: 1 from “ask” are “aask”, “bask”, “cask”, … “zask”
Edit distance can be efficiently implemented by using Dynamic programming.
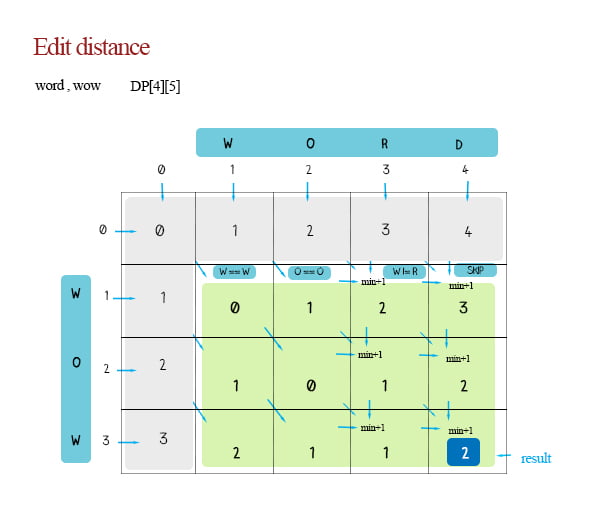
Now lets clarify the rules of “most similar” based on Edit distance:
1. It has the “closest” edit distance from the input string.
2. If multiple words have the same edit distance, the most similar word is the one with the closest edit distance that is found the most times in the dictionary.
3. If multiple words are the same edit distance and have the same count/frequency, the most similar word is the one that is first alphabetically.
Google Interview Question:
Implement a spell autocorrect with edit distance as in Google search.
Java Code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 | import java.io.*; import java.util.*; public class Autocorrector { Trie trie = new Trie(); Map<String, Integer> dict = new HashMap<>(); final static List<String> invalid = Arrays.asList("abcdefghijklmnopqrstuvwxyz"); //Time O(S), Space O(S) S is the number of words in dictionary public void useDictionary(String dictionaryFileName) throws IOException { try { FileReader fr = new FileReader(dictionaryFileName); BufferedReader br = new BufferedReader(fr); String line = null; while ((line = br.readLine()) != null) { String word = line.toLowerCase(); if (!line.contains(" ")) { dict.put(word, dict.getOrDefault(word, 0)+1); trie.add(word); } else { String[] strs= line.split("\\s"); for(String str: strs) { dict.put(str, dict.getOrDefault(str, 0)+1); trie.add(str); } } } fr.close(); br.close(); } catch (FileNotFoundException e) { System.err.println(e); } catch (IOException e) { System.err.println(e); } } //Time O(S*n*m) ~ O(S), Space(K*N), S is number of words in dictionary //K is number of edit distance, N is the max number of similar words public String suggestSimilarWord(String inputWord) { if (inputWord.length()==0 || inputWord==null || invalid.contains(inputWord.toLowerCase()) ) return null; String s = inputWord.toLowerCase(); String res=null; TreeMap<Integer, TreeMap<Integer, TreeSet<String>>> map = new TreeMap<>(); TrieNode node = trie.find(s); if(node == null) { for (String w: dict.keySet()) { int dist = editDistance(w, s); TreeMap<Integer, TreeSet<String>> similarWords = map.getOrDefault(dist, new TreeMap<>()); int freq = dict.get(w); TreeSet<String> set = similarWords.getOrDefault(freq, new TreeSet<>()); set.add(w); similarWords.put(freq, set); map.put(dist, similarWords); } res = map.firstEntry().getValue().lastEntry().getValue().first(); } else if (node !=null) { res = s; } return res; } //Time O(n*m), Space O(n*m), n is word1 length, m is word2 length private int editDistance(String word1, String word2) { int n = word1.length(); int m = word2.length(); int dp[][] = new int[n+1][m+1]; for (int i = 0; i <= n; i++) { for (int j = 0; j <= m; j++) { if (i == 0) dp[i][j] = j; else if (j == 0) dp[i][j] = i; else if (word1.charAt(i-1) == word2.charAt(j-1)) dp[i][j] = dp[i-1][j-1]; else if (i>1 && j>1 && word1.charAt(i-1) == word2.charAt(j-2) && word1.charAt(i-2) == word2.charAt(j-1)) dp[i][j] = 1+Math.min(Math.min(dp[i-2][j-2], dp[i-1][j]), Math.min(dp[i][j-1], dp[i-1][j-1])); else dp[i][j] = 1 + Math.min(dp[i][j-1], Math.min(dp[i-1][j], dp[i-1][j-1])); } } return dp[n][m]; } public static void main(String[] args) throws IOException { Autocorrector sc = new Autocorrector(); sc.useDictionary("dictionary.txt"); System.out.println("edit distance:"); System.out.println("bird -> ird: " + sc.editDistance("bird", "ird")); System.out.println("ohuse -> house: " + sc.editDistance("ohuse", "house")); System.out.println("zopper -> top: " + sc.editDistance("zopper", "top")); System.out.println("ask -> askhim: " + sc.editDistance("ask", "askhim")); System.out.println("suggest of aop is " + sc.suggestSimilarWord("aop")); System.out.println("suggest of bloat is " + sc.suggestSimilarWord("bloat")); System.out.println("suggest of reah is " + sc.suggestSimilarWord("reah")); } } |
Output:
edit distance:
bird -> ird: 1
ohuse -> house: 1
zopper -> top: 4
ask -> askhim: 3
suggest of aop is top
suggest of bloat is boat
suggest of reah is read
O Notation:
Time complexity: O(S),
S is number of words in dictionary
Space complexity: O(K*N),
K is number of edit distances, N is max number of similar words





