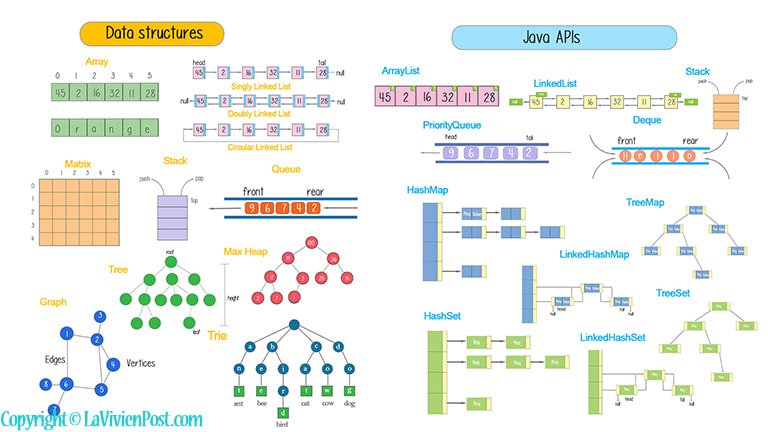
Java collections are Java built-in libraries provided by JDK. You don’t have to implement your own data structures classes and methods. You can directly call the library. Before we list the Java Collections, the original data structures are introduced. There are arrays, linked lists, stacks, binary trees, hash tables, and graphs among others. Some may not be in the library (eg trees and graphs). If you know the differences, you can choose when to use the library and when to implement your own.
Table of Content
- Data structures
- Java Collections
1. Data structures
With data structure, we find ways to make data access more efficient. When dealing with data structure, we not only focus on one piece of data but also on different sets of data and how they can relate to one another in an organized manner.
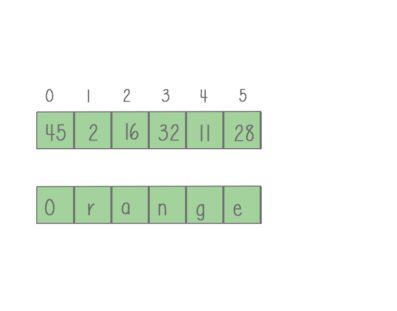
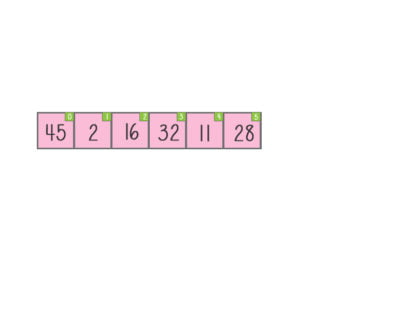
Array: An array is an index-based data structure, which means every element is referred to by an index. An array holds the same data type elements.

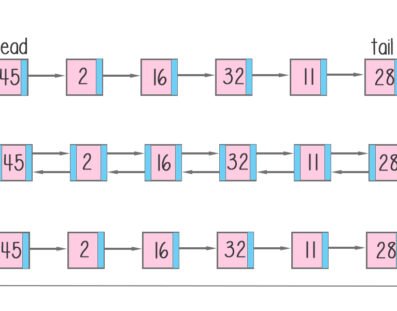
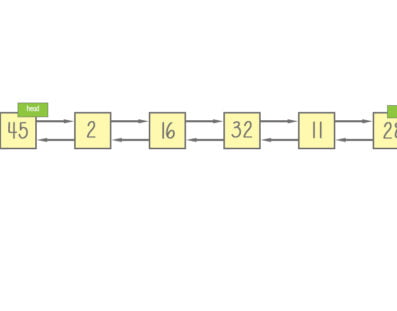
Linked list: A linked list is a sequence of nodes in which each node is connected to the node following it. This forms a chain link of data storage. It consists of data elements and a reference to the next record.
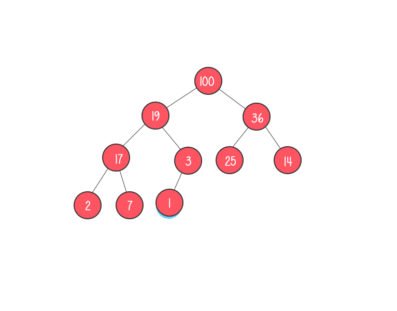
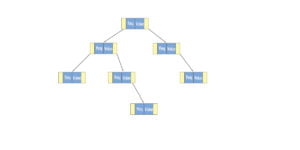
Tree: A tree is a collection of nodes connected by edges. Each node points to several nodes. A tree represents the hierarchical graphic form.
Binary tree: A binary tree has 1 or 2 nodes. It can have a minimum of zero nodes, which occurs when the nodes have NULL values.
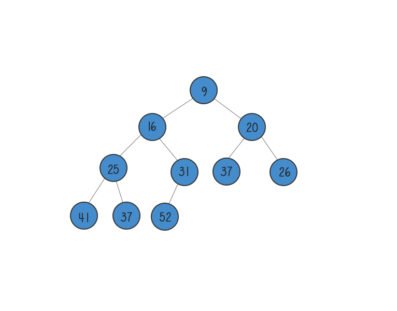
Binary search tree: A binary search tree (BST) is a binary tree. The left subtree contains nodes whose keys are less than the node’s key value, while the right subtree contains nodes whose keys are greater than or equal to the node’s key value. Moreover, both subtrees are also binary search trees. A binary search tree can retrieve data efficiently.
Matrix: A matrix is a double-dimensioned array. It makes use of two indexes rows and columns to store data.
Graph: A graph contains a set of nodes and edges. The nodes are also called vertices. Edges are used to connect nodes. Nodes are used to store and retrieve data.
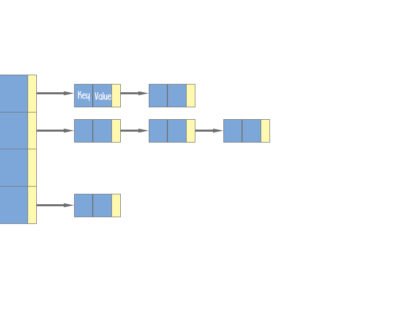
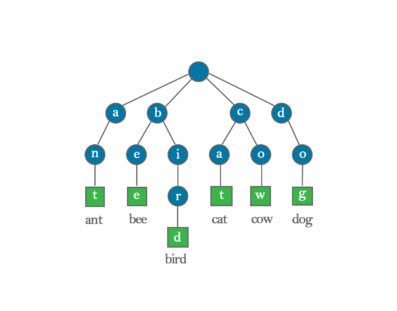
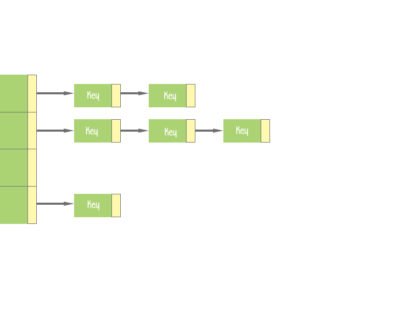
Hash table: A hash table is a data structure that can map keys to values. A hash table uses a hash function to compute a key into an integer (hash value), which indicates the index of the buckets (aka array). From the key, the correct value can be stored and found. The hash table is one of the most used data structures.
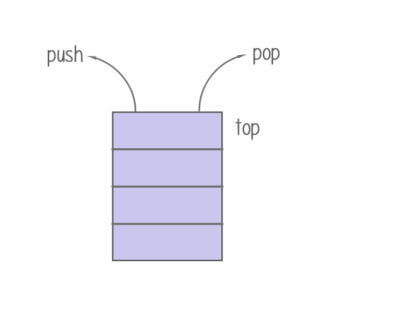
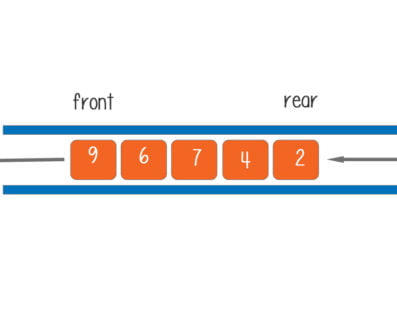
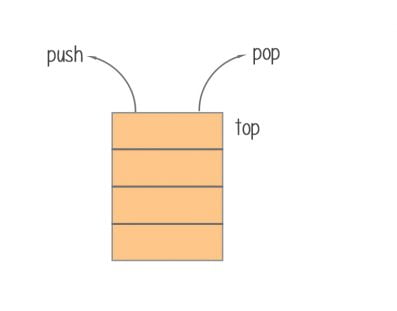
Stack: a stack is a LIFO data structure in which only the top element can be accessed. The data is added by push and removed by pop on top.
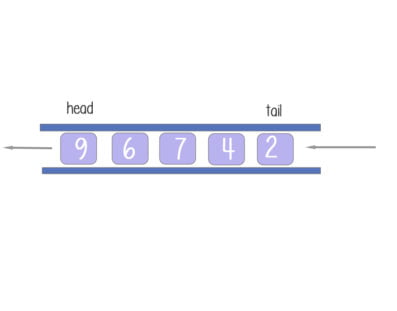
Queue: A queue is a FIFO data structure. In this structure, new elements are inserted at one end and existing elements are removed from the other end.
Priority queue: A priority queue is a queue, with each element having a priority associated with it. The implementation can use ordered array, unordered array, and heap.
Max-Heap: A heap is a tree-based data structure in which all the nodes of the tree are in a specific order. Max-heap is a binary tree. It is complete. The data item stored in each node is greater than or equal to the data items stored in its children.
Min-Heap: Min-heap is a binary tree. It is complete. The data stored in each node is less than the data items stored in its children.
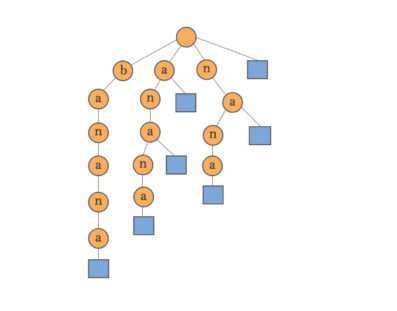
Trie: A Trie is a tree. In a trie, every node (except the root node) stores one character or a digit. By traversin/implement-min-heap/g the trie down from the root node to a particular node n, a common prefix of characters or digits can be formed which is shared by other branches of the trie as well.

Suffix trie: Suffix trie is a trie containing all the suffixes of the given text. Suffix trie allows particularly fast implementations of many important string operations.
2. Java Collections
Java collection framework is the set of collection types that are included as part of core Java. It provides the APIs or methods that you can use directly to operate on the data structures such as Arrays, Linked Lists, stacks, queues, sets, and maps. If you master Java collections, it will save you tons of time and help to solve complex problems.
ArrayList: ArrayList class is a resizable array implementation of the List interface. It implements all optional list operations and permits all elements.
Vector: Vector is very similar to ArrayList but Vector is synchronized and slow. It is a legacy class. ArrayList is preferred.
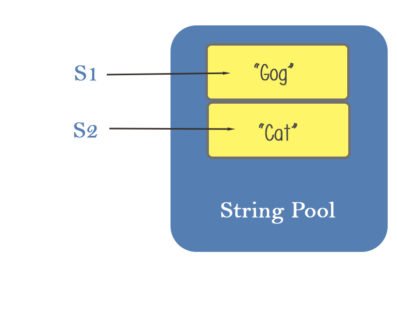
String: String class is used to create and manipulate strings.
LinkedList: The linkedList class is a doubly-linked list implementation of the List and Deque interface. A LinkedList stores its data as a list of elements and every element is linked to its previous and next element.
HashMap: A HashMap is a collection class that implements a Map interface. It requires a hash function and uses hashCode() and equals() methods, in order to put and retrieve elements to and from the collection respectively.
Hashtable: The Hashtable class is similar to HashMap. It implements a Dictionary. Hashtable provides an Enumeration of its keys. It doesn’t allow null as a key or value. Please note that since HashMap was created later, it is an advanced version and improvement on the Hashtable. Hashtable is synchronized and slower. HashMap is preferred over Hashtable.
TreeMap: TreeMap implements the SortedMap interface. It is sorted in the ascending order of its keys. The complexity of the operations is O(logn).
LinkedHashMap: LinkedHashMap keeps the inserting order. The complexity is the same as HashMap O(1).
HashSet: HashSet class implements Set interface. Duplicate values are not allowed. Its elements are not ordered. NULL elements are allowed in HashSet.
TreeSet: TreeSet is implemented using a tree structure. The elements in a TreeSet are sorted. The complexity of operations is O(logn).
LinkedHashSet: LinkedHashSet maintains the insertion order. Elements get sorted in the same sequence in which they have been added to the Set. The complexity is the same as HashSet O(1).
Stack: The stack class extends the Vector class with five operations to support LIFO (Last In First Out). Stack internally has a pointer: TOP, which refers to the top of the Stack element.
PriorityQueue: PriorityQueue class is the implementation of Queue. The elements of the priority queue are ordered according to their natural ordering, or by a Comparator provided at queue construction time.
What are the most used data structures in Java?The most used data structures in Java are ArrayList and HashMap. Others include HastSet and PriorityQueue.
What are data structures in Java Collections?· ArrayList
· LinedList
· String
· HashMap
· TreeMap
· LinkedHashMap
· HashSet
· Treeset
· LinedHashSet
· Stack
· PriorityQueue
The Data Structures Book
Related