This post compares six top Speech-to-Text (STT) models selected for their superior multilingual support and performance, and their ability to handle user accents and produce accurate transcripts close to the intended meaning, based on research conducted in 2025: ElevenLabs Scribe, AssemblyAI Universal-2, Deepgram Nova-3, Mistral Voxtral, OpenAI Whisper, and Groq Whisper-Large-v3.
The focus here is on speech recognition, including accent handling (robust recognition of non-native or regional accents) and transcript correction (post-processing to normalize errors and align with intended meaning), making these models ideal for language study (e.g., feedback on pronunciation) or translation (e.g., accurate input for multilingual processing). The comparison covers pros, cons, pricing, API key access, documentation, multilingual support, and accent-specific performance to guide learners, educators, and developers.
Table of Content
- Let’s Clear Up Some Terms First
- Groq Whisper-Large-v3
- OpenAI Whisper
- Deepgram Nova-3
- AssemblyAI Universal-2
- ElevenLabs Scribe
- Mistral Voxtral
- A quick summary
- FAQ
- Comparison of STT pricing cheat sheet
Let’s Clear Up Some Terms First
This article uses the terms WER and code-switching. If you’re unfamiliar with them, here are brief explanations.
What is WER?
WER stands for “word error rate.” In the process of recognizing speech and translating it into text form, some words may be left out or mistranslated. WER is the number of errors divided by the total words. The lower, the better. A WER of 5-10% is considered to be good quality and is ready to use.
What is code-switching?
Code-switching occurs when a speaker alternates between two or more languages. It happens a lot when a person is studying or practicing a new language.
1. Groq Whisper-Large-v3
Overview: Groq’s implementation of the Whisper-Large-v3 model, optimized for high-speed inference using Groq’s custom hardware. It leverages OpenAI’s open-source Whisper architecture for robust transcription.
Pros:
- Optimized for speed, offering fast transcription even for large audio files.
- Supports 99+ languages.
- Short-form transcription: 8.4% WER
- Speed enables quick correction loops; suitable for language study with intent-aligned transcripts
- It can be a starting point for a code-switching app.
- Cost-effective compared to some cloud-based solutions.
- Suitable for English-only use cases with the Turbo variant for enhanced speed.
Cons:
- Limited to English in the Turbo variant, reducing multilingual flexibility.
- Requires Groq infrastructure, which may limit deployment options compared to open-source Whisper.
- Lacks advanced features like diarization.
- No real-time streaming support, limiting use in live applications.
Pricing:
- ~$0.111 per hour
- More details: Groq Pricing
API Key Access: Sign up at Groq Console to obtain API keys.
Documentation: Grok models and Groq API Docs
Multilingual Support: Performs well across diverse accents and noisy environments, but accuracy may drop for less common languages. Ideal for global applications requiring broad language coverage.
2. OpenAI Whisper
Overview: OpenAI’s Whisper is an open-source STT model known for robust performance across languages and noisy conditions. Available via OpenAI’s API or self-hosted.
Pros:
- Whisper’s performance varies widely depending on the language. High accuracy (WER ~7.6%) for key languages, especially in noisy environments.
- Open-source availability allows local deployment for privacy-conscious users.
- Strong handling of technical vocabulary.
- Flexible for research and prototyping due to community-driven improvements.
Cons:
- Slower processing speed compared to Deepgram or Groq (40% of video length for large files).
- Supports 99 languages, but has limited built-in correction.
- High computational requirements for large models (1.5B parameters), needing GPUs for efficiency.
- Limited real-time streaming support, less suitable for live applications.
- API pricing can be higher than competitors for high-volume use.
Pricing:
- API: $0.006 per minute.
- Self-hosted: Free (excluding compute costs, e.g., GPU/cloud credits).
- More details: OpenAI Pricing
API Key Access: Register at OpenAI Platform for API keys. For self-hosting, download from GitHub.
Documentation: OpenAI Whisper Docs
Multilingual Support: Supports 99 languages with strong performance on major languages (e.g., English, Spanish). Accuracy decreases for low-resource languages.
3. Deepgram Nova-3
Overview: Deepgram’s Nova-3 model is a proprietary STT solution optimized for speed, accuracy, and real-time transcription, with enterprise-grade features.

Pros:
- A median WER of 6.84% on real-time audio streams.
- Good correction via custom training and sentiment analysis; handles non-native accents well for language study, but jargon issues may require manual fixes.
- Fastest transcription speed (~20s per hour of audio).
- Supports 36+ languages with real-time multilingual transcription.
- Enhanced domain-specific terminology and multilingual transcription.
- Advanced features like diarization, sentiment analysis, and self-serve customization, HIPAA-compliant.
Cons:
- Higher WER in complex scenarios
- Limited language support (36+ vs. 99 for Whisper models).
- Struggles with newly coined terms (e.g., “ChatGPT”).
Pricing:
- Nova-3 (Monolingual): $0.0036 ~ 0.0077/minute.
- Nova-3 (Multilingual): $0.0043 ~ 0.0092/minute.
- Enterprise plans: Custom pricing with discounts.
- $200 free credit for new users.
- More details: Deepgram Pricing
API Key Access: Sign up at Deepgram to access API keys.
Documentation: Deepgram API Docs
Multilingual Support: Supports 36+ languages, with low WER and real-time accent handling for key languages.
4. AssemblyAI Universal-2
Overview: AssemblyAI’s Universal-2 offers low WER and advanced NLP integrations for corrected transcripts.
Pros:
- Lowest cumulative WER (~6.68%) across diverse scenarios, outperforming most competitors.
- Excellent correction via summarization and sentiment analysis; normalizes non-native accents for language study/translation accuracy.
- Top accuracy for accented/unformatted speech. High cosine similarity for contextual correction.
- Supports 99 languages.
- Advanced features like speaker diarization, summarization, and real-time streaming.
- Easy-to-use API with high cosine similarity for accurate transcription.
Cons:
- Struggles with formatted transcription (e.g., punctuation).
- Slower than Deepgram for batch transcription (~30s per hour).
Pricing:
- Flat rate: Pre-recorded $0.27/hour, Streaming $0.15/hour.
- Advanced features (e.g., diarization): Additional costs.
- More details: AssemblyAI Pricing
API Key Access: Sign up at AssemblyAI to obtain API keys.
Documentation: AssemblyAI Docs
Multilingual Support: supports 99 languages, but WER is not as good as ElevenLabs Scribe.
5. ElevenLabs Scribe
Overview: Released in February 2025, ElevenLabs Scribe is a state-of-the-art STT model excelling in accuracy and advanced features.
Pros:
- Highest accuracy in benchmarks (~30 languages with ≤ 5% WER)
- Strong correction via diarization and timestamps; normalizes accents to produce transcripts close to intended meaning, ideal for language study feedback.
- Strong in noisy environments and complex audio.
- Supports 99 languages. Exceptional accent handling for non-native speech.
- Integrates with ElevenLabs’ TTS ecosystem.
Cons:
- Higher pricing for premium accuracy.
- Newer model with less testing on rare accents.
Pricing:
- Starter: $5 for 12h 30m. Creator: $22 for 62h 51m.
- More details: ElevenLabs Pricing
API Key Access: Sign up at ElevenLabs for API keys via the developer dashboard.
Documentation: ElevenLabs Scribe API Docs
Multilingual Support: Supports 99 languages with high accent tolerance.
6. Mistral Voxtral
Overview: Released in July 2025, Mistral’s Voxtral (3B and 24B parameters) is an open-weight STT model with multilingual accent support.
Pros:
- Low WER (~5 ~6 % in short-form audio), state-of-the-art for open models.
- Multilingual auto-detection and understanding.
- Decent correction via summarization; normalizes accents for translation/study, but limited testing on beginner accents.
- Low cost ($0.001/min) and open-source.
- Supports transcription, summarization, voice commands.
Cons:
- Newer model with limited accent benchmarks.
- Language support includes English, Spanish, French, Portuguese, Hindi, fewer than others
- Requires compute for local use.
Pricing:
- Voxtral Mini API: $0.001 per minute.
- You can download and run locally for free.
- More details: Mistral Pricing
API Key Access: Access via Mistral AI or Hugging Face.
Documentation: Mistral Docs
Multilingual Support: Supports multiple languages with auto-detection. Competitive but less comprehensive.
A Quick Summary
Ranked by effectiveness for accented language (low WER, correction features):
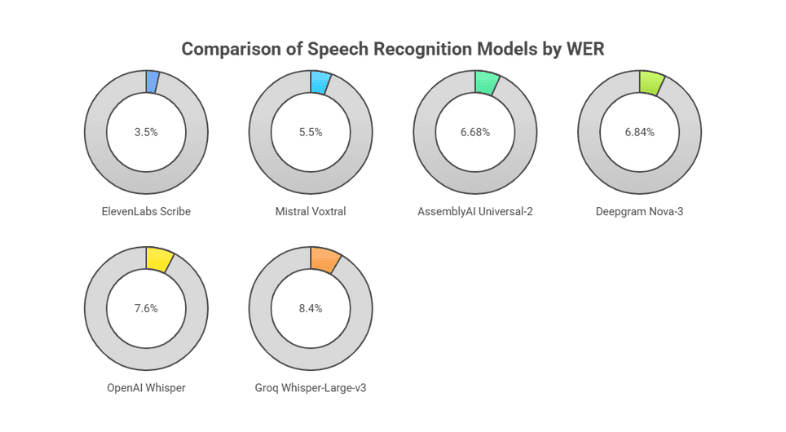
- ElevenLabs Scribe: WER ~3.5%, excellent accent normalization via diarization; best for language study feedback.
- Mistral Voxtral: WER ~5~6%, auto-detection for accents with summarization; good for study apps.
- AssemblyAI Universal-2: WER ~6.68%, robust accent handling with summarization for intent correction; ideal for translation.
- Deepgram Nova-3: WER ~6.84%, strong real-time accent tolerance; custom training aids correction.
- OpenAI Whisper: WER ~7.6%, There are language detection issues; translation features aid study.
- Groq Whisper-Large-v3: WER ~8.4%, It performs the best for code-switching. Speed supports iterative correction.
FAQ
-For language study to pick up beginner Accents: ElevenLabs Scribe for lowest WER and robust normalization.
-For Language Study with code switching: Groq Whisper-Large-v3 for support multi-language switch. However, it needs more training to be accurate.
-For Translation: Deepgram Nova-3 or Mistral Voxtral for real-time accent handling with summarization.
-Cost-Effective Options: Mistral Voxtral for open-source correction; Groq Whisper-Large-v3 for fast, affordable transcripts.
ElevenLabs Scribe for lowest WER and robust normalization.
Deepgram nova has slightly better WER (word error rate) in the chosen language. Whisper 3 is better at code-switching (a speaker alternates between two or more languages).





